Benchmark NN™ and NS™ Word Length Reduction Systems
An overview of the word length reductions systems incorporated in the AD2404-96 family of converters.
The AD2404-96 and the SONIC AD2K+ are equipped with two state of the art world length reduction systems: The Benchmark NN™ (Near Nyquist) system, and the Benchmark NS™ (Noise Shaped) system. Unlike most competitive systems, the Benchmark NS™ system is based upon the most current psycho-acoustic models. Furthermore, both Benchmark systems are unique in that they were optimized while factoring in the noise contribution of the recording environment.
The Benchmark NN™ and NS™ word length reduction systems are the result of a cooperative effort between Benchmark Media Systems, Inc., and the Audio Lab at the University of Waterloo in Ontario Canada. We would especially like to thank Stanley P. Lipshitz Ph.D., John Vanderkooy Ph.D., and Robert A. Wannamaker Ph.D. for their pioneering research and for their significant contributions to the early stages of this project. Special thanks are also in order to Robert Wannamaker for creating and modifying the mathematical algorithms and filter coefficients which are at the core of the Benchmark NN™ and NS™ systems.
We have taken a new approach by optimizing word length reduction for use in three different levels of ambient noise. The ambient noise in a live recording situation is very different from ambient noise level in a studio, and neither can be considered insignificant when reducing 24-bit recording to 16-bits. All prior word-length-reduction systems ignored the effects of this ambient noise and were optimized for noise-free input signals. The Benchmark NN™ and NS™ systems were mathematically optimized while calculating the effects of ambient noise. Three levels of input noise were used and three different curves were produced. NN3™ and NS3™ represent optimal solutions where system noise is limited only by the 24-bit A/D conversion process. NN2™ and NS2™ represent optimal solutions where the ambient noise is 6 dB higher than the converter noise floor. NN1™ and NS1™ represent optimal solutions where the ambient noise is 12 dB higher than the converter noise floor. When properly used, this optimization can improve the dynamic range of a finished 16-bit recording by several decibels.
What is the Appropriate Setting to Use?
In general, NN3™ or NS3™ should be used for extremely low-noise studio recording environments, NN2™ or NS2™ should be used for live recording, while NN1™ and NS1™ should be reserved for noisy recording environments. The greatest possible dynamic range will be achieved when the proper function is selected.
The choice of NN™ versus NS™ is mostly a matter of preference while the choice of curves 1, 2 or 3 is largely dependent upon the dynamic range of the source material. Here are a few general guidelines that should be followed:
1. If very high playback levels are anticipated, (i.e. playback gain will be high enough for the noise floor to be heard), use the NN™ settings as these produce natural sounding noise floors. 2. If the source material has been subjected to a prior 16-bit word length reduction process, select NN3™ for subsequent processing. 3. If low to moderately high playback levels are anticipated (i.e. playback gain will be low enough that the noise floor is inaudible), use the NS™ settings as these yield the greatest dynamic range. 4. The NS™ functions can achieve lower psycho-acoustic noise levels than the corresponding NN™ functions. 5. When in doubt concerning ambient noise levels, use a higher numbered function. 6. When in doubt concerning anticipated playback levels, use an NN™ function. 7. When totally in doubt, use NN3™ and then try other settings as you gain familiarity with the system. 8. The mathematically inclined can use the charts in appendix 1 to calculate dynamic range, and the audibility of the various NN™ and NS™ functions.
While each of the Benchmark NN™ and NS™ processes have been optimized for certain levels of ambient noise contribution, it is important to point out that the processes do not rely on this noise for dithering. TPDF dither is always applied to the 24-bit signal prior to word length reduction. The NN™ and NS™ processes are always fully dithered to insure full randomization of the quantization noise, and to insure that the quantization noise is de-correlated from the audio signal. Any of the NN™ and NS™ processes can be used on any source without the risk of distortion that can result from an inadequate dither process. Furthermore, the NN™ and NS™ processes can be used in cascade without any ill effects other than a slight increase in the noise floor.
What Happens when NN™ or NS™ Processes are used in Cascade?
Every time the number of generations is doubled, the noise-floor will increase by 3 dB. For example, two passes through a NN™ or NS™ process will reduce the dynamic range by 3 dB (as compared to the results obtained after only one pass). After 4 passes through a NN™ or NS™ process, the dynamic range will have decreased by an additional 3 dB for a total of 6 dB. And after the 8th pass, the dynamic range will have decreased by a total of 9 dB. The charts below show the results of cascaded processes. Please note that the noise of a first generation 16-bit process is at or slightly above the threshold of audibility. Multiple passes through 16-bit word length reduction processes will raise the noise floor above the threshold of audibility, and should therefore be avoided when possible. If there is no alternative, and 16-bit word length reduction must be cascaded, NN3™ or NS3™ should be used for the first process, while NN3™ should be used for all subsequent processing steps.
Why is NN3™ Recommended for Cascaded 16-bit Processes?
The NN™ processes produce a noise floor that sounds very much like white noise. On the other hand, the NS™ processes produce a colored noise floor and are best suited for applications where this noise floor is below the threshold of hearing. The advantage of using a NS™ process is that the dither noise will remain inaudible at higher playback levels, than if a corresponding NN™ process were used. IF the NS™ dither noise exceeds the threshold of audibility (due to cascaded processing or very high playback levels), the NS™ process will yield better results. The reason for this is that the natural sound of white noise is less distracting than colored noise even when the colored noise is at a slightly lower level.
Dither
Reducing a 20-bit or 24-bit audio to 16-bits always requires the addition of dither noise. Failure to add a source of dither prior to each truncation process will create distortion in the output. Remember that dither noise is of a very low level, and remains inaudible or nearly inaudible until the gain of a playback system is made extremely high.
A good word length reduction system will remain inaudible during quiet portions of a recording, even when the playback system is adjusted to achieve high peak sound pressure levels. Dither that is audible will tend to mask musical details. This masking effect of dither increases as the audibility of the dither increases.
While it is desirable to keep the dither inaudible, it is also necessary to apply enough dither to fully randomize the noise added by word length reduction. The Benchmark NN™ and NS™ systems provide full randomization and are carefully designed for minimum audibility. Benchmark word length reduction systems never add distortion. They only add very low-level random noise. Unlike other noise reduction systems, this low-level noise is not effected by the musical signal.
TPDF dither (white noise dither), will always be more audible than the dither noise produced by a well-designed word length reduction system. The Benchmark 16-bit 44.1-kHz NS3™ system yields a whopping 14 dB improvement over 16-bit TPDF. 16-bit 44.1 kHz NS3™ will remain inaudible unless play back levels are adjusted such that a 0 dBFS signal exceeds 107 dB SPL. In contrast, 16-bit TPDF dither will become audible when playback levels are adjusted such that a 0 dBFS signal exceeds 93 dB SPL. Please note, at these gain settings, the dither will only begin to be audible when there is a point of full silence in the recording, and then only when the room itself is also sufficiently quiet. Dither noise is never audible in the presence of a 0 dBFS signal.
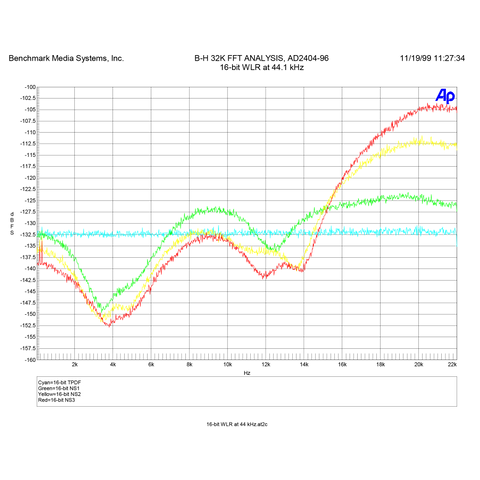
16-bit NS™ Word Length Reduction Curves for 44.1 kHz
The 16-bit 44.1-kHz NS3™ noise shaping curve (shown above) provides a 14-dB improvement over 16-bit TPDF, in terms of noise audibility.
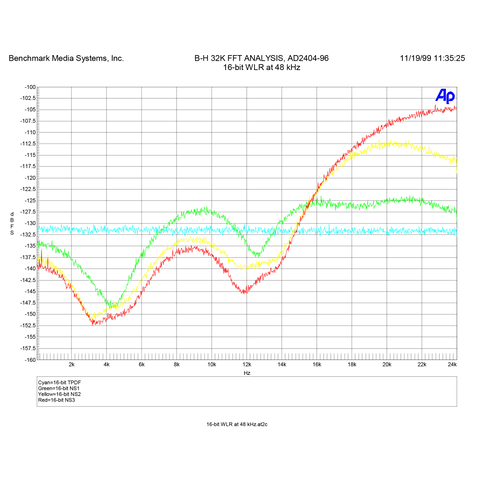
16-bit NS™ Word Length Reduction Curves for 48 kHz
The 16-bit, 48-kHz NS3™ curve (shown above) has a 17-dB advantage over 16-bit TPDF.

16-bit NS™ Word Length Reduction Curves for 96 kHz
The 16-bit, 96-kHz NS3™ curve (shown above) provides a 28-dB improvement over 16-bit TPDF.
Will Dither Noise Damage My Speakers?
Please note that nothing bad happens when the gain of a playback system is increased enough to hear dither noise. Dither will not blow out your speakers, unless possibly someone inadvertently turns on an audio source while the amplifier is in this high gain state! Remember that dither is an extremely low-level signal (much like tape hiss, only of a much lower level).
How is the Performance of a Word Length Reduction System Measured?
The audibility of dither can be expressed in terms of "F-Weighted Noise Power". The F-weighting function is derived from measurements of the ear's sensitivity to very low level signals. At 16-bits, 44.1-kHz the F-weighted noise power of TPDF dither is -93.3 dBFS and the F-weighted noise power of NS3™ is -107.5 dBFS. In other words, 16-bit TPDF dither provides a 93.3 dB noise-free dynamic range, while NS3™ provides a much greater 107.5 dB noise-free dynamic range.
All word length reduction systems add noise to the audio, it is a law of mathematics. However, the noise can be placed anywhere within the bandwidth of the digital system. If the noise is evenly spread out over the entire bandwidth (as it is with TPDF dither), the system will yield the lowest possible unweighted noise when measured on an audio analyzer. But, a uniform noise distribution is not the best solution from an audibility standpoint. Our ears are not equally sensitive to all frequencies within the 0 to 22.05 kHz bandwidth of a 44.1 kHz digital system. The audibility of the added noise is greatly reduced when it is concentrated at frequencies where our ears are least sensitive. Near-Nyquist systems reduce noise audibility by concentrating most of the noise energy between 18 kHz and the Nyquist frequency (1/2 of the sample rate) while maintaining a relatively flat and natural sounding noise floor below 16 kHz. Noise-Shaped systems attempt to achieve the greatest possible noise improvement by distributing the noise in a function that is the inverse of the ear’s sensitivity. TPDF will read the lowest on the meters, but will always sound louder than a good word-length-reduction system. Don’t let the meters fool you! Remember, unlike your ears, most meters “hear” equally well at all frequencies.
Avoid Truncation without Dither
There are numerous potential sources of noise within an A/D converter. These may include thermal noise, noise from a delta sigma modulation process, cross talk, clock feed-through, etc. None of these sources of noise are added intentionally, but in many cases these noise sources may be of a high enough level to allow truncation without the addition of a dither signal. For example, many 20-bit A/D converters have enough self-noise to allow their outputs to be truncated to 16-bits without ill effects. Similarly many 24-bit converters have enough self-noise to allow truncation to 20-bits. Many recording engineers have discovered that they can truncate the outputs of their A/D converters without causing distortion. Do not try this with the AD2404-96 or the AD2K+! These are very quiet 24-bit converters, and it do not have enough self-noise to provide adequate dither for truncation to 20-bits (nor 16-bits). For this reason it is imperative to use one of the 20-bit output settings when feeding 20-bit devices, and one of the 16-bit settings when feeding 16-bit devices. Remember that truncation without adequate dither will cause distortion.
One additional caution concerning truncation: Each world length reduction process requires a new source of dither noise. For example, consider a signal starts out at 24-bits and is dithered down 16-bits. Lets suppose we take this 16-bit signal and feed it into a 24-bit digital audio workstation, and apply a minor gain change or a touch of EQ. This 16-bit signal has now become a 24-bit signal inside the workstation. If the final product is going to be 16-bits, a second 24 to 16-bit word length reduction process must be applied. Some have assumed that it is not necessary to add dither in the second process because it was already added in the first process. However, truncation to 16-bits at the output of the workstation will add distortion to the audio. Instead, use the digital to digital word length reduction feature in the AD2404-96 and the AD2K+ to reduce the word length back to 16-bits. Remember every word length reduction process requires a new source of dither noise.
Digital Word Length Increases when a Signal is Processed
Every time a digital signal is processed, its word length increases. "Processing" includes even simple operations such as level changes and the mixing of two signals. Word lengths expand dramatically when more complex operations such as equalization, sample rate conversion, and effects processing are applied. Long word lengths created by digital signal processing must be shortened before they can be re-recorded or sent to a DAC for monitoring.
Every time a digital word length is shortened, a new source of noise must be added to the signal prior to truncation. Dither noise that was applied for one truncation operation is not useful for dithering a subsequent truncation operation. Failure to add a new source of noise prior to each truncation process will create distortion. The self-noise of an A/D converter, the noise of the mic-pre, and ambient noise. Again, every word length reduction process requires a new source of dither noise.
Additional Information
Dither by Bob Katz
Dither - Wikipedia






